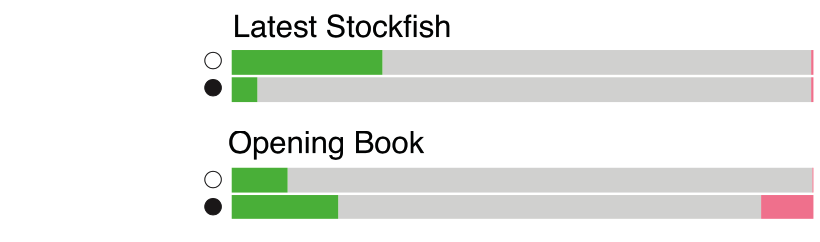
The average number of unique states visited by AlphaZero and Go-Exploit
Por um escritor misterioso
Descrição

AlphaZero Explained · On AI

Adaptive Design of Alloys for CO2 Activation and Methanation via Reinforcement Learning Monte Carlo Tree Search Algorithm
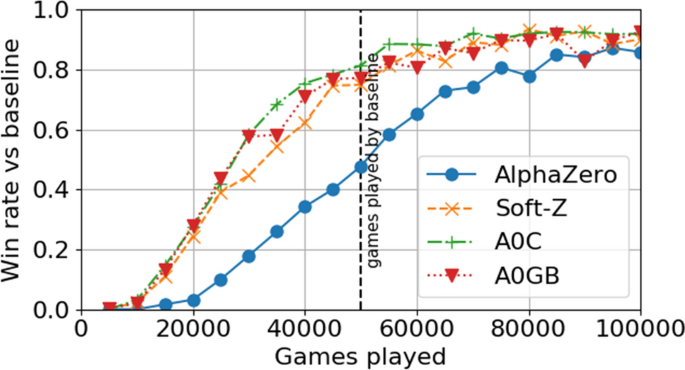
Value targets in off-policy AlphaZero: a new greedy backup

Monte Carlo Tree Search - A Quick Introduction (with Code) - Dilith Jayakody
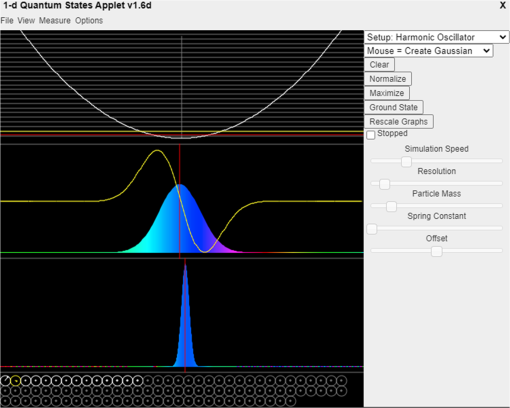
Quantum games and interactive tools for quantum technologies outreach and education

The average number of unique states visited by AlphaZero and Go-Exploit

Targeted Search Control in AlphaZero for Effective Policy Improvement – arXiv Vanity

Science Magazine - December 7, 2018 - Building two-dimensional materials one row at a time: Avoiding the nucleation barrier

Student of Games: A unified learning algorithm for both perfect and imperfect information games

Even Superhuman Go AIs Have Surprising Failure Modes — LessWrong

Artificial intelligence meets radar resource management: A comprehensive background and literature review - Hashmi - 2023 - IET Radar, Sonar & Navigation - Wiley Online Library

Student of Games: A unified learning algorithm for both perfect and imperfect information games
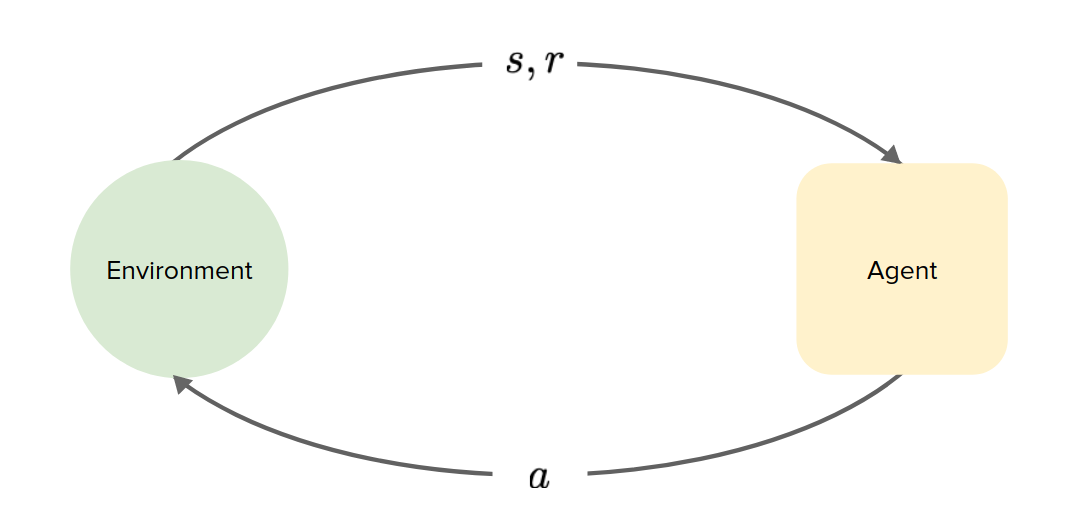
Model-Based Reinforcement Learning (MBRL), by Isaac Kargar
When Alpha Zero is making seemingly bizarre moves in chess is it actually predicting what its opponent will do (calculating possibilities), or is it setting up its own attack/defense based on positional
de
por adulto (o preço varia de acordo com o tamanho do grupo)